Pengantar Retrieval-Augmented Generation (RAG)
RAG (Retrieval-Augmented Generation) adalah teknik canggih yang menggabungkan kekuatan Large Language Models (LLM) dengan sistem pencarian informasi (retrieval) untuk menghasilkan respons yang lebih akurat, up-to-date, dan berbasis fakta.
Sebagai AI engineer, RAG adalah salah satu skill paling penting yang harus kalian kuasai untuk membangun aplikasi AI yang production-ready dan dapat memberikan informasi yang reliable.
Masalah dengan LLM Standar
Meskipun powerful, LLM tradisional memiliki beberapa keterbatasan fundamental yang membuat mereka kurang ideal untuk aplikasi production yang membutuhkan akurasi tinggi:
Keterbatasan LLM Standar
- Knowledge Cutoff: Terbatas pada data training, tidak tahu info terbaru
- Hallucination: Sering membuat informasi yang terdengar benar tapi salah
- Tidak Ada Source: Tidak bisa memberikan referensi atau sumber informasi
- Generik: Tidak bisa akses knowledge base atau dokumen spesifik perusahaan
Keunggulan RAG
- Real-time Knowledge: Bisa akses informasi terbaru dari database
- Grounded Response: Jawaban berdasarkan dokumen yang ada, mengurangi hallucination
- Traceable: Bisa menunjukkan sumber informasi yang digunakan
- Domain-specific: Bisa dilatih pada knowledge base khusus perusahaan
Konsep Dasar RAG
RAG menggabungkan dua komponen utama: Retrieval System (sistem pencarian) dan Generation System (LLM) untuk menciptakan AI yang lebih pintar dan reliable.
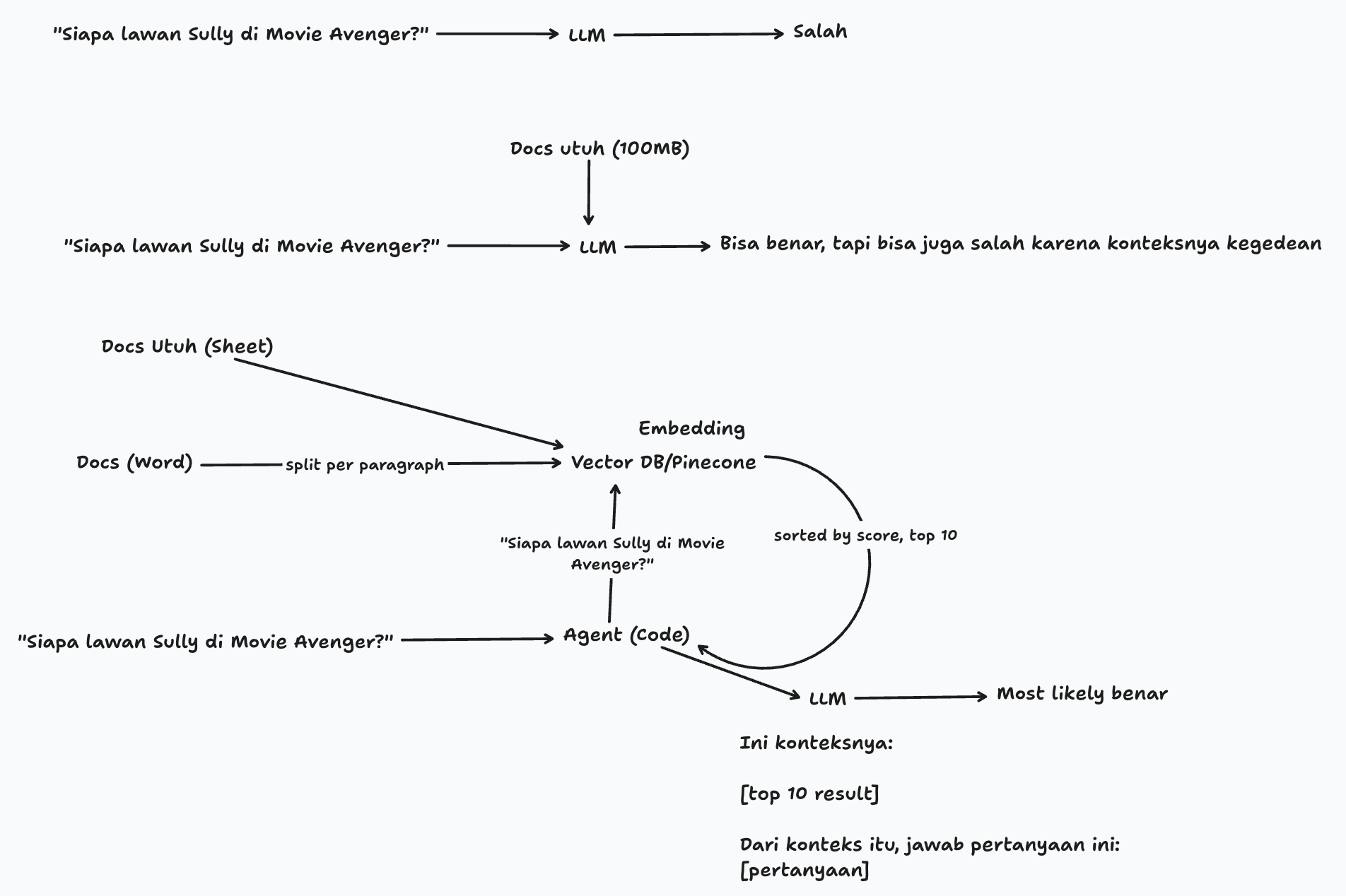
Diagram konsep RAG: Dari pertanyaan sederhana hingga jawaban dengan konteks yang relevan
RAG = Retrieval + Augmentation + Generation
Retrieval
Cari informasi relevan
Augmentation
Gabungkan dengan query
Generation
Generate respons final
Smart AI
Jawaban akurat & reliable
Analogi Sederhana:
Bayangkan kamu sedang ujian open book. Ketika dapat pertanyaan, kamu tidak langsung jawab dari ingatan, tapi kamu buka buku untuk cari informasi yang relevan, lalu gunakan informasi itu untuk menyusun jawaban yang tepat. Itulah konsep RAG!
Cara Kerja RAG: Step by Step
Mari kita breakdown bagaimana RAG bekerja dari user query hingga menghasilkan respons final. Memahami flow ini penting untuk implementasi yang efektif.
User Query
User bertanya: "Apa kebijakan cuti terbaru di perusahaan?"
Query Embedding
Konversi query ke vector representation menggunakan embedding model
Similarity Search
Cari dokumen/chunk yang paling relevan di vector database
Retrieve Context
Ambil top-k dokumen yang paling mirip (misal 3-5 dokumen teratas)
Prompt Augmentation
Gabungkan user query dengan retrieved context dalam prompt
LLM Generation
LLM generate respons berdasarkan context yang diberikan
Contoh Augmented Prompt:
Vector Database: Otak RAG System
Vector database adalah jantung dari sistem RAG. Di sinilah semua knowledge disimpan dalam bentuk embeddings yang bisa dicari dengan semantic similarity, bukan hanya keyword matching.
Proses Indexing:
Split dokumen jadi chunks kecil (200-500 tokens)
Konversi setiap chunk jadi vector (1536 dimensi)
Simpan di vector DB dengan metadata
Popular Vector Databases:
Pinecone
Managed vector DB, mudah digunakan, cocok untuk production
Weaviate
Open-source, built-in vectorization, GraphQL API
Chroma
Lightweight, perfect untuk development dan prototyping
Qdrant
Rust-based, high performance, filtering capabilities
Milvus
Open-source, scalable, enterprise-grade features
FAISS
Facebook AI, in-memory, excellent untuk research
Embedding Models: Translator ke Vector Space
Embedding models bertugas mengkonversi teks (baik dokumen maupun query) menjadi vector representations yang bisa dibandingkan secara matematis untuk mengukur semantic similarity.
Keyword Search (Traditional)
Query: "mobil cepat"
Match: Dokumen yang mengandung kata "mobil" DAN "cepat"
Miss: "kendaraan bermotor berkecepatan tinggi"
Semantic Search (Embeddings)
Query: "mobil cepat"
Match: Semua dokumen dengan makna serupa
Hit: "kendaraan bermotor berkecepatan tinggi", "otomotif performa tinggi"
Popular Embedding Models:
OpenAI text-embedding-ada-002
1536 dimensi, balanced performance, $0.0001/1K tokens
OpenAI text-embedding-3-small
1536 dimensi, improved performance, lebih murah
OpenAI text-embedding-3-large
3072 dimensi, highest quality, untuk use case critical
Sentence Transformers
Open-source, bisa dijalankan locally, berbagai model size
Cohere Embeddings
Multilingual support, good untuk non-English content
Hugging Face Models
Free, open-source, bisa fine-tune untuk domain spesifik
Retrieval System: Mencari Jarum di Tumpukan Jerami
Retrieval system bertanggung jawab mencari dan mengembalikan dokumen yang paling relevan dengan user query. Ada beberapa strategi retrieval yang bisa digunakan tergantung use case.
Retrieval Strategies:
1. Dense Retrieval (Semantic Search)
Menggunakan embeddings untuk mencari semantic similarity. Bagus untuk menemukan konteks yang relevan meski kata-katanya berbeda.
2. Sparse Retrieval (Keyword Search)
Traditional keyword matching (BM25, TF-IDF). Bagus untuk exact matches dan proper nouns.
3. Hybrid Retrieval
Kombinasi dense + sparse retrieval. Memberikan hasil terbaik untuk kebanyakan use case.
4. Multi-stage Retrieval
Retrieve banyak dokumen dulu, lalu re-rank dengan model yang lebih sophisticated.
Retrieval Parameters:
- Top-k: Berapa banyak dokumen yang di-retrieve (biasanya 3-10)
- Similarity threshold: Minimum score untuk dianggap relevan
- Chunk overlap: Overlap antar chunks untuk konteks yang better
- Metadata filtering: Filter berdasarkan kategori, tanggal, dll
LLM Integration: Menggabungkan Semuanya
Tahap final adalah mengintegrasikan retrieved context dengan LLM untuk menghasilkan respons yang coherent, accurate, dan helpful. Di sini prompt engineering skill kalian akan sangat berguna.
Prompt Template untuk RAG:
Best Practices LLM Integration:
- Clear instructions: Jelaskan peran LLM dan batasan-batasannya
- Context formatting: Format retrieved docs dengan clear separators
- Source attribution: Minta LLM untuk cite sumber informasi
- Fallback handling: Handle case ketika tidak ada relevant context
- Response formatting: Specify format output yang diinginkan
Popular LLM Choices untuk RAG:
GPT-4 / GPT-3.5-turbo
Excellent instruction following, good untuk production
Claude-3 (Anthropic)
Large context window (100K tokens), good untuk long documents
Llama 2 / Code Llama
Open-source, bisa self-host, good untuk privacy-sensitive use cases
Gemini Pro
Google's model, good integration dengan Google ecosystem
Implementasi RAG dengan n8n
Mari kita lihat bagaimana mengimplementasikan RAG system menggunakan n8n workflow. Berikut adalah contoh workflow yang akan kalian gunakan dalam praktik.
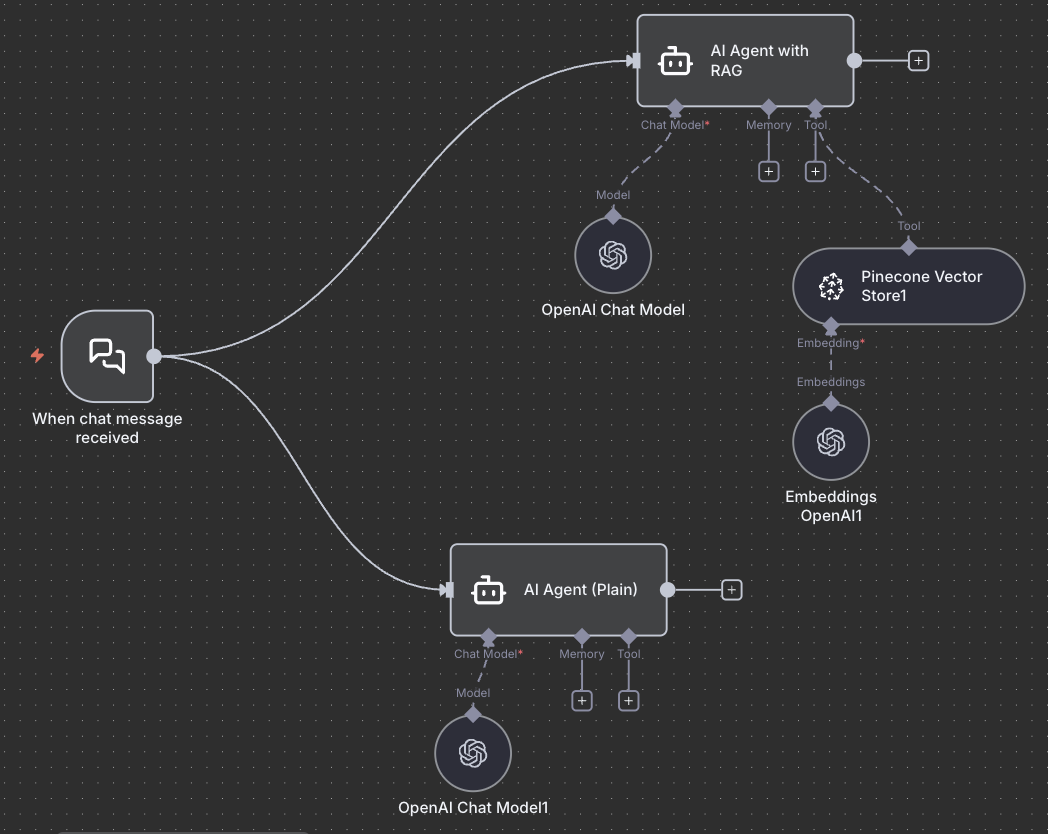
Contoh implementasi RAG menggunakan n8n workflow dengan AI Agent, Pinecone Vector Store, dan OpenAI
Use Cases & Applications
RAG memiliki aplikasi yang sangat luas, dari customer support hingga internal knowledge management. Mari kita explore berbagai use case yang bisa kalian implementasikan sebagai AI engineer.
Popular RAG Applications:
Document Q&A
Menjawab pertanyaan dari manual, policy, atau knowledge base perusahaan
Customer Support
Intelligent chatbot yang bisa akses FAQ, troubleshooting guides, product info
News & Content Analysis
Summarize berita terbaru, analyze trends, generate insights dari content
Internal Assistant
Help employees dengan HR policies, IT procedures, company information
Educational Tools
Interactive learning dari textbooks, research papers, course materials
Legal & Compliance
Search legal documents, analyze regulations, compliance checking