Apa itu Seq2Seq?
User: Siapa penemu lampu bohlam?
AI: Penemu lampu bohlam adalah Thomas Alva Edison. Ia merupakan seorang penemu dan pengusaha berkebangsaan Amerika Serikat. Edison menemukan lampu pijar yang praktis pada tahun 1879.
Sequence-to-sequence, atau seq2seq, adalah arsitektur model yang menerima input berupa sequence (urutan) kata dan menghasilkan output berupa sequence kata juga. Kita memberikan sebuah sequence, model membalas dengan sequence lain—makanya disebut sequence-to-sequence.
Arsitektur Keseluruhan
Model seq2seq terdiri dari dua komponen utama: encoder dan decoder. Kedua komponen bekerja sama untuk mengubah input dengan panjang variatif menjadi output dengan panjang variatif pula.
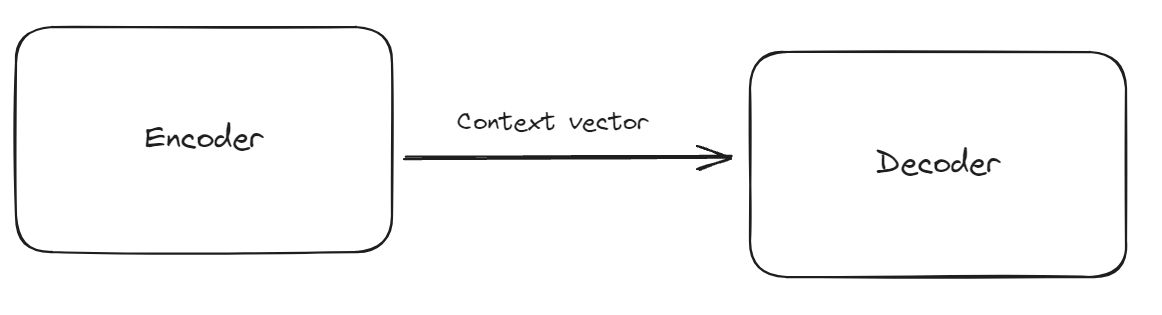
Peran Encoder dan Decoder
Berikut gambaran singkat mengenai tugas masing-masing komponen dalam arsitektur seq2seq:
- Encoder menggunakan arsitektur RNN many-to-one.
- Decoder menggunakan arsitektur RNN one-to-many.
- Context vector adalah hidden state terakhir dari encoder yang menjembatani encoder dan decoder.
Diagram di bawah membantu memvisualisasikan aliran informasi antara encoder dan decoder.

Kenapa Seq2Seq untuk NLP?

Setiap kalimat dapat dipandang sebagai sebuah sequence. Panjang sequence input maupun output bisa berbeda-beda, sehingga arsitektur encoder-decoder menjadi pilihan alami untuk tugas seperti penerjemahan, rangkuman, atau dialog.
After several minutes of waiting, Afista's patience grow thinner & he leaves
Seperti manusia, model perlu membaca kalimat secara utuh sebelum bisa menghasilkan terjemahan yang masuk akal. Dengan encoder, kita membiarkan model "membaca" input kata demi kata. Context vector menampung pemahaman tersebut, dan decoder bertugas menuliskannya kembali dalam bentuk sequence baru.
- Encoder membaca input dan membentuk representasi tersembunyi.
- Context vector membawa pemahaman encoder ke decoder.
- Decoder menghasilkan output kata demi kata sampai token akhir.
Pendekatan ini memungkinkan panjang input dan output berbeda. Contoh: pertanyaan 12 kata bisa dijawab dengan kalimat 16 kata, sesuatu yang sulit dicapai jika kita memaksa panjang sequence tetap.
Context Vector
Context vector adalah jembatan antara encoder dan decoder. Ia memadatkan informasi penting dari seluruh input menjadi satu vektor numerik.
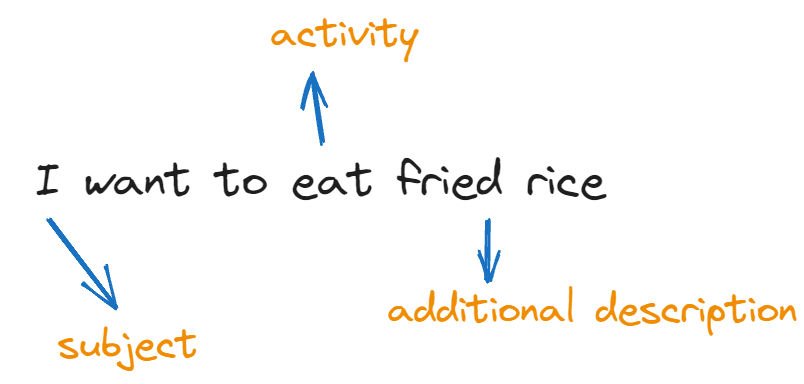
Bayangkan sebuah vector tiga dimensi yang berisi: subjek, aktivitas, dan deskripsi tambahan.
[.., .., ..]Kita bisa memetakannya ke kamus sederhana untuk memahami idenya:
subject:
0 - I
1 - You
2 - He
activity:
0 - eat
1 - drink
2 - write
additional description:
0 - fried rice
1 - orange juice
2 - a novel
Contoh konversi kalimat menjadi context vector:
I want to eat fried rice -> [I, eat, fried rice] -> [0, 0, 0]
You want to drink orange juice -> [You, drink, orange juice] -> [1, 1, 1]
He wants to write a novel -> [He, write, a novel] -> [2, 2, 2]Inti: context vector adalah rangkuman padat dari keseluruhan input. Pada implementasi nyata, dimensinya bisa sangat besar dan dihitung otomatis melalui pembelajaran.
Diagram Encoder-Decoder
Gambar berikut memperlihatkan bagaimana context vector menghubungkan encoder dan decoder dalam satu alur pemrosesan.
Encoder
Encoder menggunakan RNN many-to-one. Ia membaca sequence kata secara berurutan dan merangkum maknanya ke dalam context vector.
Sebelum masuk ke encoder, kata-kata diubah menjadi token angka lalu diproyeksikan ke vector melalui layer embedding. Dengan cara ini, model dapat belajar representasi yang bermakna untuk setiap kata.
I want to eat fried rice -> [I, eat, fried rice] -> [0, 0, 0]
You want to drink orange juice -> [You, drink, orange juice] -> [1, 1, 1]
He wants to write a novel -> [He, write, a novel] -> [2, 2, 2]Dalam konteks encoder, context vector identik dengan final hidden state—keadaan tersembunyi terakhir setelah seluruh input selesai dibaca.
Decoder
Decoder menggunakan RNN one-to-many. Ia menerima context vector dan menghasilkan sequence output satu token pada satu waktu.
-
Context vector menjadi initial hidden state dan token
pertama adalah simbol khusus
<s>. - Setelah menghasilkan kata pertama, decoder menggunakan kata itu sebagai input berikutnya.
-
Proses berlanjut hingga model memprediksi token akhir
</s>atau mencapai panjang maksimum.
Rangkuman
- Seq2Seq memetakan sequence input ke sequence output menggunakan pasangan encoder-decoder.
- Encoder menyerap informasi dengan RNN many-to-one dan menghasilkan context vector.
- Decoder memanfaatkan context vector untuk menghasilkan output step-by-step melalui RNN one-to-many.
- Context vector adalah ringkasan numerik dari seluruh input dan menjadi titik awal decoding.
- Pendekatan ini fleksibel terhadap perbedaan panjang input dan output—kritis untuk tugas NLP seperti terjemahan.