Word2Vec: Menghasilkan Word Embedding
Di sesi sebelumnya, kita telah melihat kekuatan dari word embedding. Sekarang kita akan melihat bagaimana cara menghasilkan word embedding menggunakan Word2Vec!
Dalam pembelajaran ini, kita akan memahami:
- Konsep Word2Vec - Bagaimana neural network belajar word embedding
- Skip-gram Model - Memprediksi konteks dari kata
- CBOW Model - Memprediksi kata dari konteks
- Simulasi Interaktif - Lihat bagaimana Word2Vec bekerja
Konsep Word2Vec
Konsepnya cukup simpel jika kita coba untuk dalami dulu intuisinya:
- Input: One-hot encoded vector yang merepresentasikan input word kita
- Hidden Layer: Setiap neuron merepresentasikan konteks berbeda yang didapatkan dari training (tense, gender, dll)
- Output Layer: Menggunakan softmax untuk menghasilkan probabilitas untuk setiap word di vocabulary
Prinsip Utama:
Kata-kata yang muncul dalam konteks yang sama cenderung memiliki makna yang berhubungan. Word2Vec memanfaatkan prinsip ini untuk membangun representasi vektor.
Intuisi: Menghubungkan Words
Mari kita lihat contoh sederhana untuk memahami bagaimana Word2Vec belajar:
Contoh 1: "king" dan "ruler"
Jika kita membaca banyak kalimat seperti:
- "the king ordered the citizens to leave the city"
- "the ruler ordered the citizens to leave the city"
- "the king commanded the citizens to evacuate the city"
- "the ruler commanded the citizens to evacuate the city"
Contoh 2: "fish" dan "water"
Perhatikan kalimat-kalimat ini:
- "fish swims in the water"
- "the water is home to many fish"
- "the fish is dead because of the polluted water"
- "water is essential for fish to live"
Pertanyaan:
"fish" dan "water" sering muncul bersamaan. Haruskah kita menyimpulkan bahwa mereka dekat satu sama lain di vector space?
Jawaban: Ya! Word2Vec akan belajar bahwa kedua kata ini memiliki hubungan yang erat.
Skip-gram: Memprediksi Konteks
Skip-gram memprediksi kata-kata dalam range tertentu sebelum dan sesudah sebuah kata dalam sebuah kalimat.
Contoh dengan Window Size = 2
Kalimat: "I love to eat fish, but I hate to drink water"
| Window Size | Input | Predicted Output |
|---|---|---|
| 2 | love | (I, to, eat) |
| 2 | eat | (love, to, fish, but) |
| 2 | fish | (to, eat, but, I) |
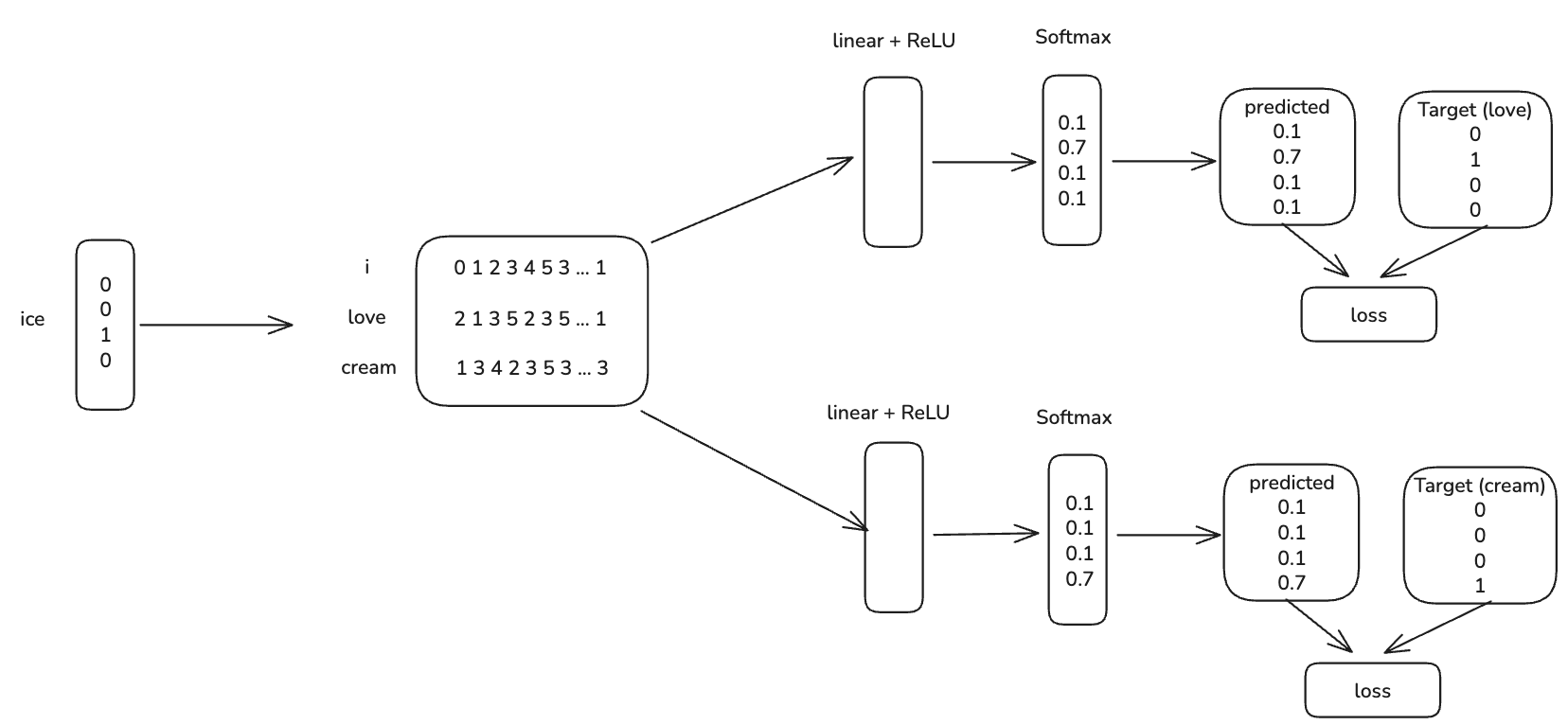
CBOW: Continuous Bag of Words
CBOW adalah kebalikan dari Skip-gram. Ini memprediksi kata tengah berdasarkan konteks dari beberapa kata sebelum dan sesudahnya.
Contoh dengan Window Size = 2
Kalimat: "I love to eat fish, but I hate to drink water"
| Window Size | Input (Context) | Predicted |
|---|---|---|
| 2 | ( I, to eat) | love |
| 2 | (love to, fish, but) | eat |
| 2 | (to eat, but I) | fish |
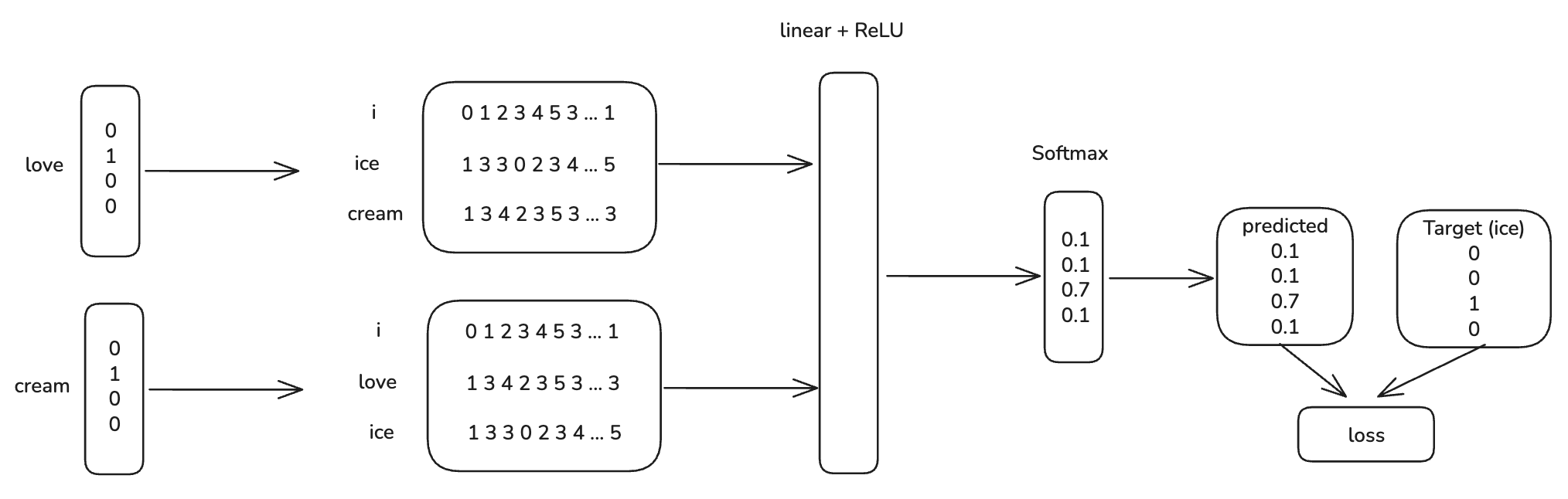
Perbandingan:
- Skip-gram: Lebih baik untuk dataset kecil, belajar dari kata langka
- CBOW: Lebih cepat, lebih baik untuk dataset besar
Simulasi: Cara Kerja Skip-gram & CBOW
Klik sebuah kata pada kalimat di bawah untuk melihat bagaimana Skip-gram dan CBOW memproses kata tersebut.
Kalimat Simulasi
Pasangan Data Training
Klik sebuah kata pada kalimat...
Simulasi: Bagaimana Relasi Terbentuk
Kata-kata yang muncul dalam konteks yang sama cenderung memiliki makna yang berhubungan. Perhatikan contoh di bawah ini.
Contoh Kalimat (Corpus)
the wise king sits on the royal throne
the wise queen sits on the royal throne
a good king is a just ruler
a good queen is a just ruler
Analisis Konteks
Konteks untuk king:
Kata-kata yang muncul di dekat "king": wise, sits, on, royal, throne, good, is, just, ruler
Konteks untuk queen:
Kata-kata yang muncul di dekat "queen": wise, sits, on, royal, throne, good, is, just, ruler
Kesimpulan
Karena king dan queen sering muncul dalam konteks yang sangat mirip (dikelilingi oleh kata-kata yang sama), Word2Vec menyimpulkan bahwa keduanya memiliki relasi semantik yang kuat. Vektor mereka akan menjadi sangat berdekatan.
Implementasi Word2Vec
Cara termudah untuk membangun Word2Vec model adalah dengan menggunakan library gensim.
💻 Praktikkan di Google Colab
Implementasikan Word2Vec dengan library Gensim secara langsung
Buka di Google ColabRangkuman: Word2Vec
Selamat! Anda telah mempelajari Word2Vec, teknik fundamental untuk menghasilkan word embedding.
Poin-Poin Penting
- Word2Vec: Neural network 2-layer untuk word embedding
- Skip-gram: Prediksi konteks dari kata tengah
- CBOW: Prediksi kata tengah dari konteks
- Prinsip: Kata dalam konteks sama memiliki vektor mirip
- Window Size: Menentukan range konteks yang dipertimbangkan
- Training: Belajar dari co-occurrence patterns dalam corpus
Keunggulan Word2Vec
- Menghasilkan dense vectors yang menangkap semantic meaning
- Kata dengan makna mirip memiliki vektor yang dekat
- Mendukung operasi aritmatika pada kata (king - man + woman ≈ queen)
- Efisien dan scalable untuk corpus besar
Skip-gram vs CBOW
| Aspek | Skip-gram | CBOW |
|---|---|---|
| Input | Kata tengah | Kata konteks |
| Output | Kata konteks | Kata tengah |
| Kecepatan | Lebih lambat | Lebih cepat |
| Dataset Kecil | Lebih baik | Kurang optimal |
| Kata Langka | Lebih baik | Kurang optimal |