Feature Extraction: Dari Teks ke Angka
Setelah preprocessing, kita perlu mengubah teks bersih menjadi angka. Proses ini disebut feature extraction atau ekstraksi fitur.
Mengapa perlu diubah menjadi angka? Karena algoritma machine learning hanya bisa memproses data numerik, bukan teks langsung.
Metode yang akan kita pelajari:
- Bag of Words (BoW) - Menghitung frekuensi kata
- TF-IDF - Memberikan bobot berdasarkan kepentingan
- N-grams - Mempertimbangkan urutan kata
Bag of Words (BoW)
Bag of Words adalah metode paling sederhana untuk mengubah teks menjadi vektor angka. Bayangkan Anda memiliki "kantong kata" dan menghitung berapa kali setiap kata muncul.
Contoh sederhana:
Dokumen 1: "saya suka python"
Dokumen 2: "saya suka machine learning"
Dokumen 3: "python bagus untuk machine learning"
Vocabulary: [bagus, untuk, learning, machine, python, saya, suka]
Vektor Dokumen 1: [0, 0, 0, 0, 1, 1, 1]
Vektor Dokumen 2: [0, 0, 1, 1, 0, 1, 1]
Vektor Dokumen 3: [1, 1, 1, 1, 1, 0, 0]
Kelebihan:
- Sederhana dan mudah dipahami
- Cepat untuk diimplementasikan
- Efektif untuk banyak tugas klasifikasi teks
Kekurangan:
- Tidak mempertimbangkan urutan kata
- Tidak membedakan kata penting vs tidak penting
- Menghasilkan vektor yang sparse (banyak nilai 0)
Demo: Bag of Words
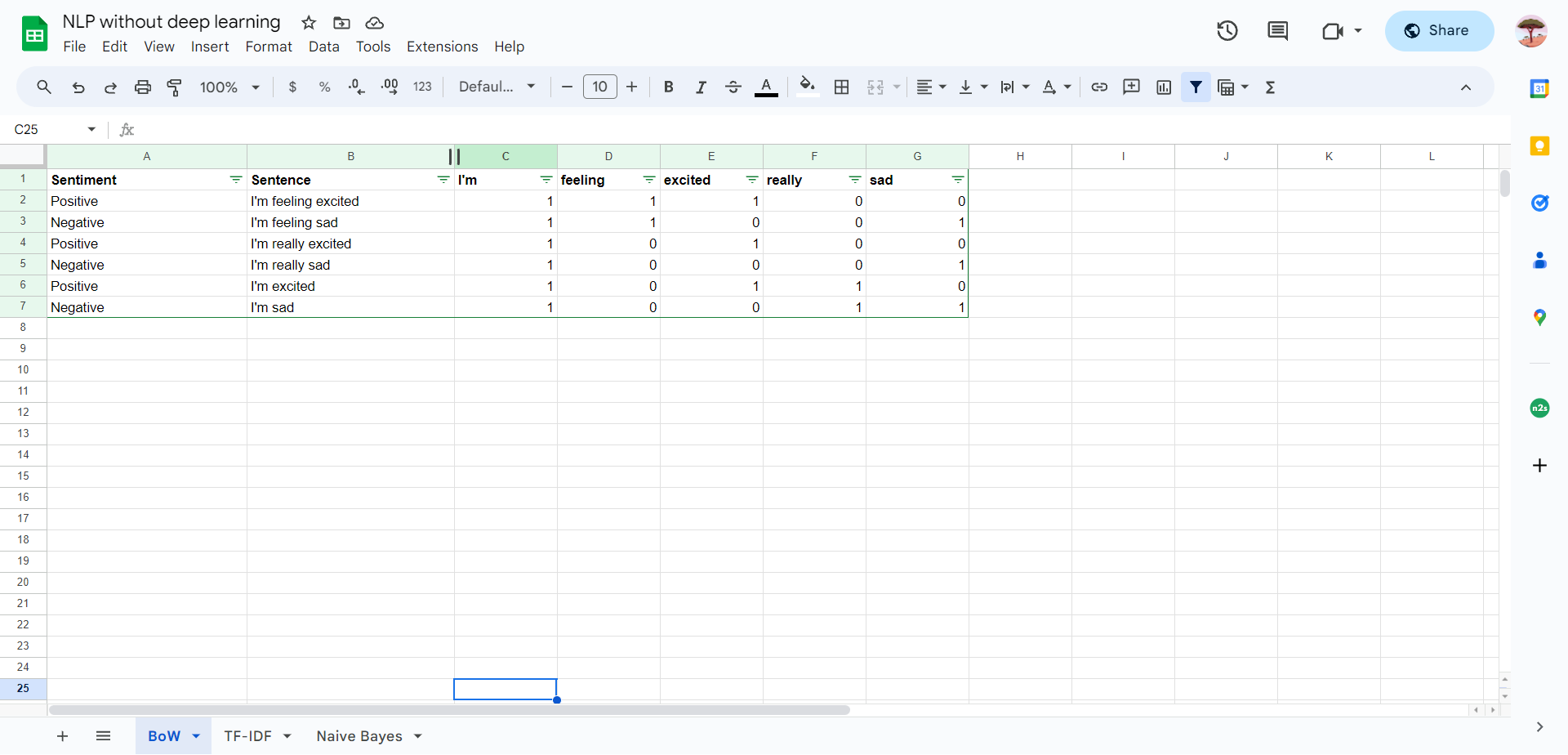
Mari kita lihat bagaimana Bag of Words bekerja dengan contoh visual:
📊 Lihat Spreadsheet Interaktif
Eksplorasi perhitungan Bag of Words secara detail dengan spreadsheet interaktif
Buka Google Spreadsheet
Jadi untuk setiap kata di dalam training set kita, kata-kata tersebut akan memiliki dimensi khusus masing-masing, dan kita hanya menghitung di setiap kalimat berapa banyak masing-masing kata muncul.
TF-IDF: Term Frequency - Inverse Document Frequency
TF-IDF adalah perbaikan dari Bag of Words. Metode ini memberikan bobot lebih tinggi pada kata yang sering muncul dalam dokumen tertentu tapi jarang muncul di dokumen lain.
Komponen TF-IDF:
- TF (Term Frequency): Seberapa sering kata muncul dalam dokumen
- IDF (Inverse Document Frequency): Seberapa unik kata tersebut di seluruh koleksi dokumen
Formula:
TF-IDF(kata, dokumen) = TF(kata, dokumen) × IDF(kata)
IDF(kata) = log(Total Dokumen / Jumlah Dokumen yang mengandung kata)
Contoh:
Kata "python" muncul di 2 dari 3 dokumen → IDF rendah
Kata "bagus" muncul di 1 dari 3 dokumen → IDF tinggi
Demo: TF-IDF Math

Untuk pembelajaran TF-IDF kita, kita akan menggunakan dataset sebelumnya yang kita gunakan untuk Bag-of-words kita, dan mari kita lihat bagaimana TF-IDF akan membantu kita untuk mengurangi kepentingan kata "Aku" karena terus muncul di seluruh dataset.
📊 Lihat Spreadsheet Interaktif
Eksplorasi perhitungan TF-IDF secara detail dengan spreadsheet interaktif
Buka Google SpreadsheetIDF Calculation
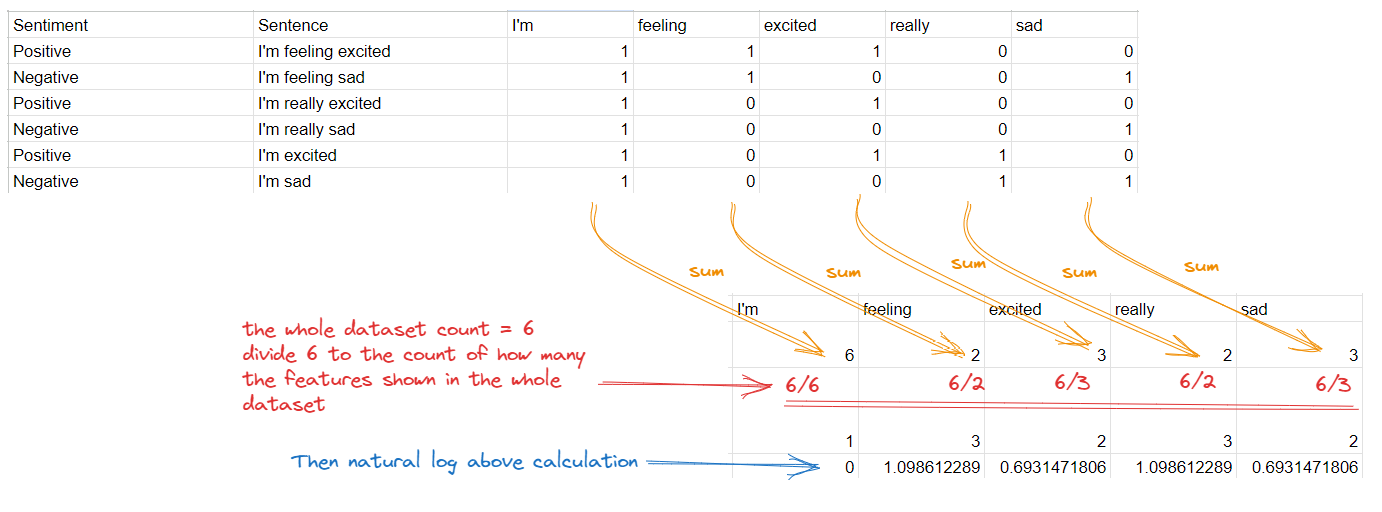
Perhitungan IDF untuk sebuah fitur sangatlah sederhana:
TF-IDF = TF × IDF
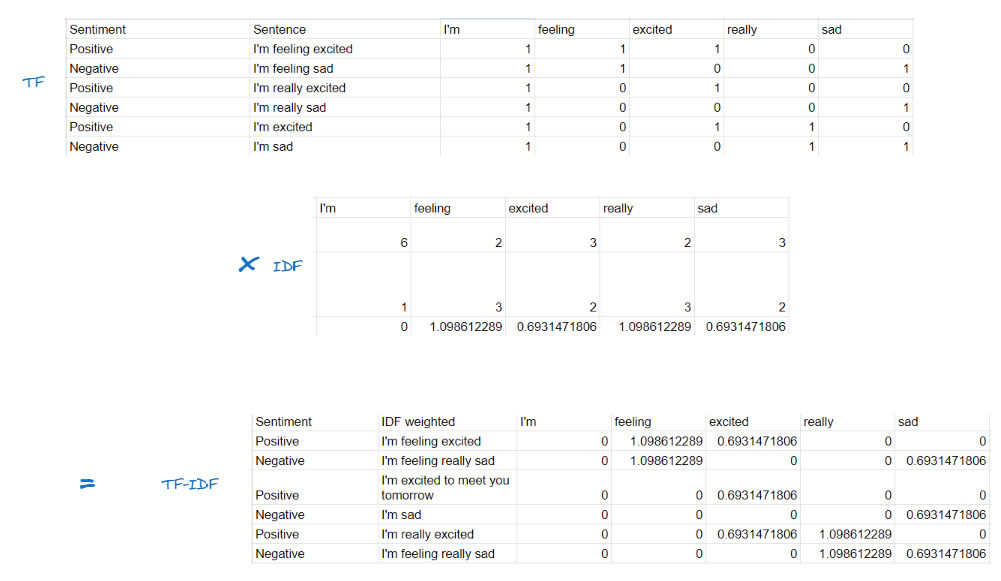
TF-IDF kemudian dapat dihitung dengan hanya mengalikan TF untuk semua input ke IDF. Kemudian kita akan melihat skor di bawah ini:
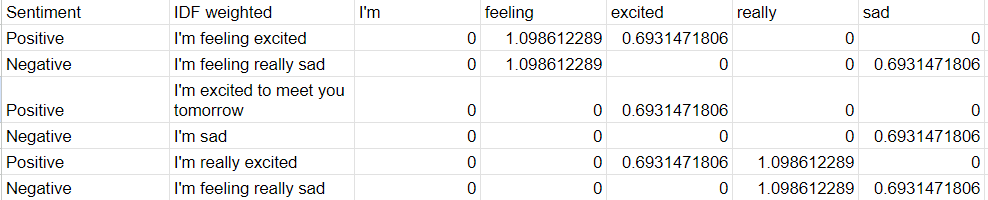
Seperti yang bisa kita lihat di atas, kata-kata seperti "Aku", karena pada dasarnya terlihat di setiap dataset, menggunakan ini untuk menganalisis sentimen tidak akan berguna. Sedangkan untuk kata-kata lain, kata-kata tersebut sekarang diprioritaskan berdasarkan kemunculannya.
Simulasi Interaktif: BoW vs TF-IDF
Sekarang mari kita lihat perbedaan antara Bag of Words dan TF-IDF dengan dataset nyata (80 ulasan restoran)!
Dataset Training
80 ulasan restoran yang sudah dilabeli sebagai positif atau negatif. Klik tombol di atas untuk melihat dataset lengkap.
Perhatikan: Grafik menampilkan kata-kata yang paling diskriminatif (membedakan) antara kelas positif dan negatif.
Naive Bayes Classifier
Naive Bayes adalah salah satu cara paling sederhana untuk melakukan klasifikasi teks tanpa neural network. Konsepnya sangat mirip dengan intuisi kita: Menemukan kata-kata yang bisa memberikan petunjuk ke arah klasifikasi apa pun, sambil tidak memberikan klasifikasi apa pun ke "kata-kata netral". Berikut adalah contoh bagaimana melakukan naive bayes dengan menggunakan BOW sebagai fitur ekstraksi kita:
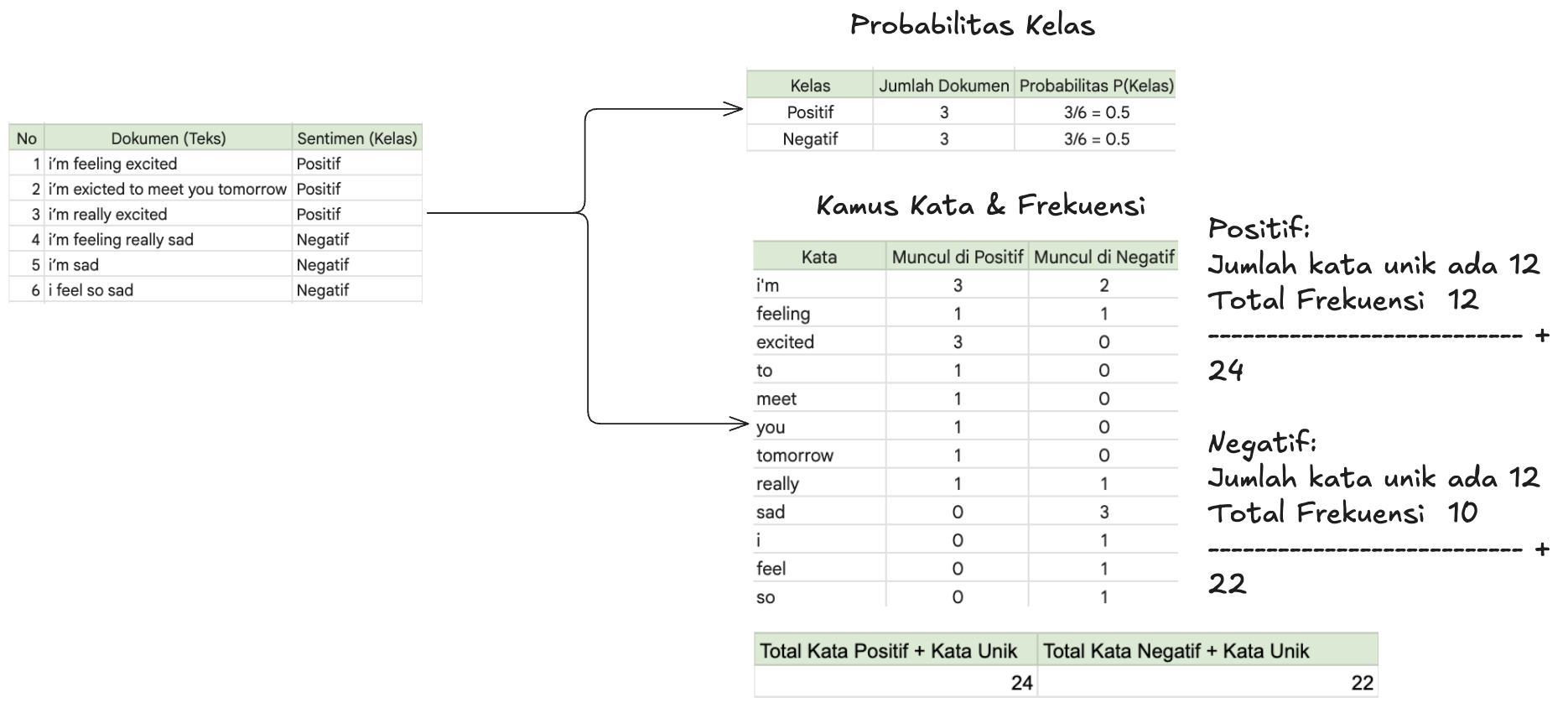
Operasinya sederhana untuk menghitung probabilitas di setiap kata:

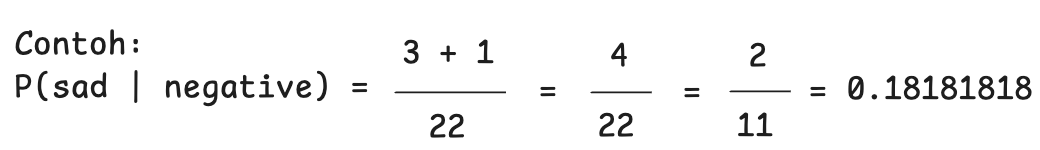
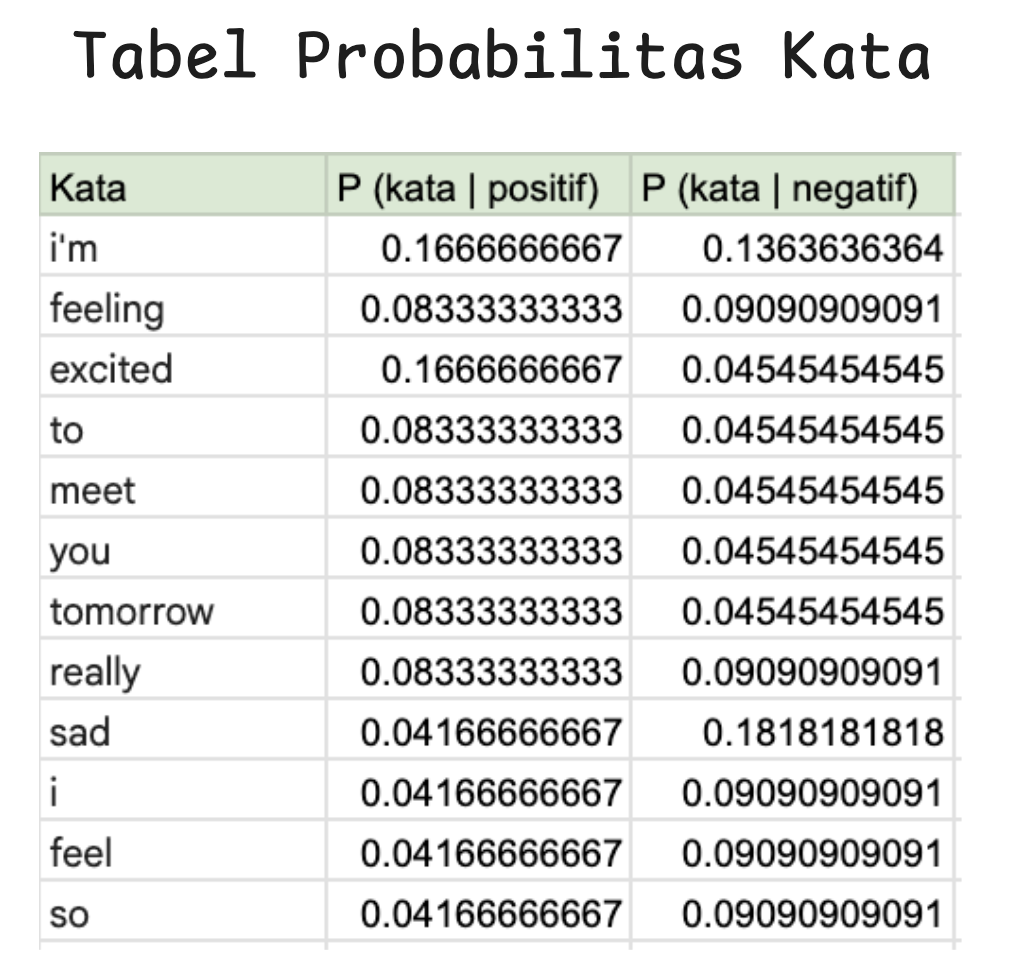
Sekarang, mari kita uji kalimat baru: "I'm so excited".
Kita hitung probabilitas untuk masing-masing kelas (Positif dan Negatif).
Untuk Kelas Positif:
Rumusnya adalah mengalikan Probabilitas Kelas Positif dengan Probabilitas masing-masing kata di kelas Positif. Begitu pula dengan kelas Negatif.

Seperti yang kamu bisa lihat di atas, menggunakan Naive Bayes classifier kita bisa mendapat setiap kata yang dapat memberi petunjuk bahwa sebuah sentimen itu positif, negatif, atau netral.
- Kata-kata positif akan memiliki skor yang lebih tinggi pada sentimen positif
- Kata-kata negatif akan memiliki skor yang lebih tinggi pada sentimen negatif
- Kata-kata netral akan memiliki skor yang mirip pada kedua sentimen
Training Model
Klik tombol di bawah untuk melatih model Naive Bayes menggunakan fitur yang telah diekstrak (BoW atau TF-IDF).
Testing: Uji Coba Model
Sekarang kita bisa mencoba memasukkan kalimat yang belum pernah dilihat oleh Naive Bayes kita sebelumnya. Mari kita lihat prosesnya:
Contoh Input: "Aku merasa sangat sedih"
Langkah-langkahnya sesederhana mengekstrak fitur kita menjadi seperti di bawah ini:
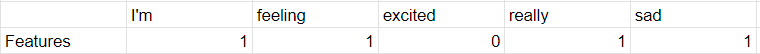
Kemudian setelah itu kita kalikan dengan TF-IDF kita untuk setiap klasifikasi, lalu kita akan mendapatkan skor untuk setiap kata yang ada di input kita:
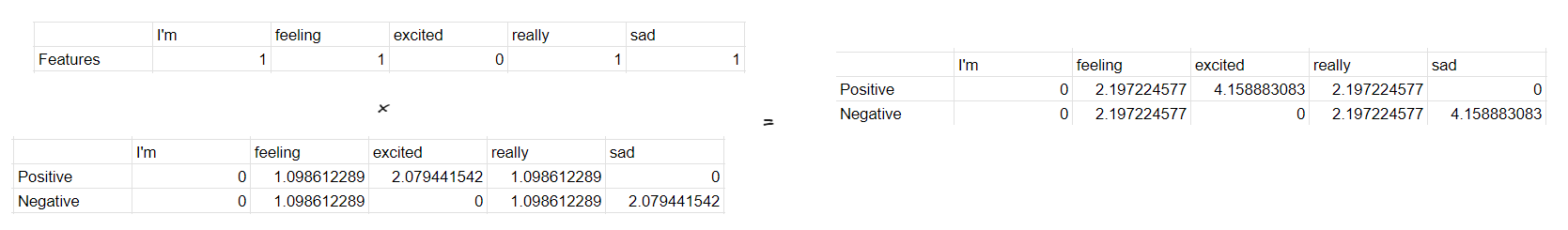
Setelah itu untuk mengetahui klasifikasi apa kalimat kita diklasifikasikan menurut Naive Bayes kita, kita bisa menjumlahkan skor per fitur menjadi skor tunggal untuk setiap klasifikasi:
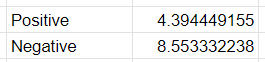
Jadi menurut Naive Bayes kita, kalimat "Aku merasa sangat sedih", diklasifikasikan ke dalam sentimen negatif 💥.
Coba Model Sendiri
Gunakan simulasi interaktif di bawah untuk mencoba dengan teks Anda sendiri!
Cara kerja: Model menghitung probabilitas untuk setiap kelas berdasarkan kata-kata yang ada dalam input Anda. Kelas dengan probabilitas tertinggi adalah prediksi akhir.
Rangkuman: Feature Extraction
Selamat! Anda telah mempelajari konsep dan implementasi feature extraction dalam NLP. Mari kita rangkum:
Poin-Poin Penting
- Bag of Words: Menghitung frekuensi kata, sederhana tapi efektif
- TF-IDF: Memberikan bobot pada kata berdasarkan kepentingan
- Feature Extraction: Mengubah teks menjadi vektor numerik
- Naive Bayes: Classifier probabilistik yang cocok untuk teks
- Trade-off: BoW lebih sederhana, TF-IDF lebih informatif